Funnel chart to track time utilization (with real interactive report in Power BI).
This report was created for a real client, a coal mining company. All numbers were modified to hide metrics. In this post i show my approach to creating a funnel chart that shows time utilization. Dashboard utilizes basic (default) chart available in Power BI (Stacked bar chart). Further i will explain how i built this.
The idea (and requirements) was to build a funnel that flows from top to bottom. It starts with
total available time
(as percentage of total 24/7 time available eg. 100%) and then deducts time spent on each
category
(also as percentage of total available time).
A little twist here was to add a few
breakpoints that show stages of mining equipment readiness.
For expample there s a "Ready for work" stage that assumes all main
technical maintenance is done and managers can view the time (as percentage of total) equipment
(heavy duty loaders)
can operate in field.
The next stage "Effective work time" is a break point metric that shows how much (in %%) the
loader was actually busy with main work.
Another little twist was to add switcher to view linear or weighted average (weighted by
the excavator ladle volume)
time utilization.
* Below is the actual (interactive) report. Note there s no MOBILE view available, so better open your desktop/laptop and try it out (though it still will work on your mobile device).
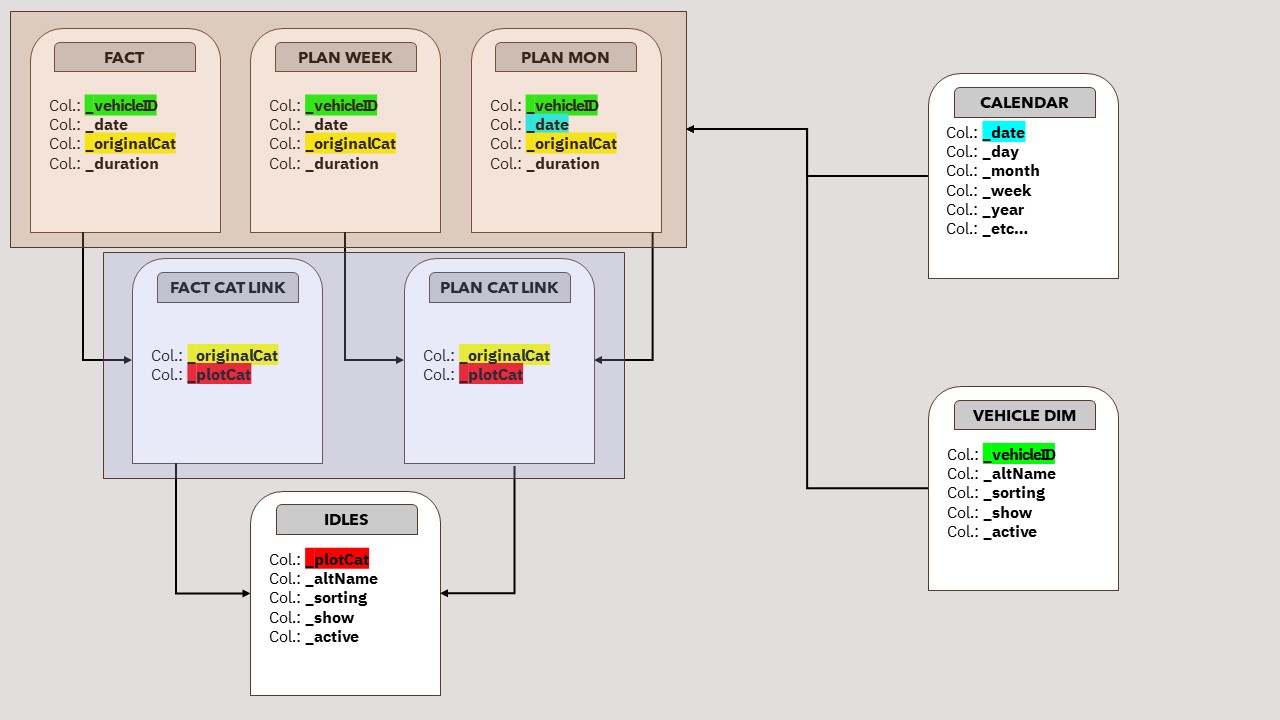
Model
First we need to layout and structure the Fact table (actually Fact and two Plan table since there are two types of plan). The Fact/Plan table looks like this:
| _vehicleID | _date | _idleCategory | _duration |
|---|---|---|---|
| LDR-1250-SP-3068 | 04/01/2023 | Total time | 86 400 |
| Visa - 6076 | 14/05/2032 | Maintenance | 4 804 |
...
So basically we need 4 columns:
We need one line for every day for every vehicle to calculate total time available (it would be 86 400 sec or 24 hours).
So with these 3 tables setup (fact, weekly plan, monthly plan) we now need a few more tables to build a model:
- A link table for Fact (since there are a lot of low level categories in Fact table we need to group them into more high level categories)
- A link table for Weekly Plan (the same idea with categories for both plan tables)
- A link table for Monthly Plan (the same idea with categories for both plan tables)
- High level Idles table (we will use this table to create categories in the chart)
- A Calendar table
- Dimension table with vehicles and their corresponding fields and offices
I used intermediary tables for Fact/Plan since some idle categories in Fact and Plan did not match. And also it was easier to work with separate intermediary tables when debugging.
As a little side note: for this report i had to create a custom Calendar table with business week starting on Saturday and ending on Friday. In one of my next blog posts i will share my solution in PowerQuery M code.
So basically having all our tables loaded into model we just need to link them together:
- Fact > Fact (link table) > Idles table
- Weekly plan > Weekly plan (link table) > Idles table
- Monthly plan > Monthly plan (link table) > Idles table
- Calendar >>> Fact, Plan tables (Calendar links to all fact, plan tables)
- Dimension table with vehicles >>> Fact/Plan tables
Finaly the basic skeleton of the model would look like this:
Measures
To solve the problem we need to remember a few things:
- To have a category plotted on a chart axis - it must be physically present in a table
- We would need three Measures to create the funnel chart:
- Calculate total time spent for ordinary categories
- Calculate breakpoints
- Calculate bars that will fill blank space
Odrinary categories time calculation
Lets start with the measure: calculate (sum up) time spent for each ordinary category (linear time utilization). Then get to the weighted average measure. And after we ll run through the logic.
VAR _breakPoint = SELECTEDVALUE('_idlesDIM'[Sorting])
VAR _base = ADDCOLUMNS(
SUMMARIZE('_vehiclesDIM',
'_vehiclesDIM'[_vehicleName]),
"@active",
CALCULATE(
MAXX('_FACT','_FACT'[_active]),
REMOVEFILTERS('_idlesDIM'[idle_model_category])),
"@hours",
CALCULATE(
SUMX(
FILTER('_FACT',
'_FACT'[_active] = 1),
'_FACT'[duration])) / 3600,
"@totalHours",
CALCULATE(
SUM('_FACT'[duration]),
FILTER(ALL('_idlesDIM'),
'_idlesDIM'[Sorting] = 1)) / 3600)
RETURN
SWITCH(TRUE(),
_breakPoint IN {1,6,24,27},0,
DIVIDE(
SUMX(_base, [@hours]),
SUMX(_base, [@totalHours])))
Next lets calculate time utilization for ordinary categories but with a twist (weighted average: excavators ladle volumes will act as weights)
VAR _breakPoint = SELECTEDVALUE('_idlesDIM'[Sorting])
VAR _base = ADDCOLUMNS(
SUMMARIZE('_vehiclesDIM',
'_vehiclesDIM'[_vehicleName]),
"@vol",
CALCULATE(
MAXX('_vehiclesDIM','_vehiclesDIM'[_ladleVolume])),
"@active",
CALCULATE(
MAXX('_FACT','_FACT'[_active]),
ALL('_idlesDIM')),
"@hours",
CALCULATE(
SUMX(
FILTER('_FACT',
'_FACT'[_active] = 1),
'_FACT'[duration])) / 3600,
"@totalHours",
CALCULATE(
SUM('_FACT'[duration]),
FILTER(ALL('_idlesDIM'),
'_idlesDIM'[Sorting] = 1)) / 3600)
VAR _percent = ADDCOLUMNS(
FILTER(_base,
[@active] = 1),
"@percent",
[@hours] / [@totalHours]))
RETURN
SWITCH(TRUE(),
_breakPoint IN {6,24,27},
0,
DIVIDE(
SUMX(_percent, [@percent] * [@vol]),
SUMX(_percent, [@vol])))
So the logic in these two measures is pretty much the same:
- In the VAR called _breakPoint we capture the current item on the plot (eg Total time, maintenance, Conservation etc) that will be used in the RETURN statement
- VAR _base is the virtual table where we add columns with attributes:
- First we get unique values of excavators
- Then we add attribute @active which will show if the excavator was active during selected period
- Another attribute will be @hours where we sum up hours from the fact/plan table
- And finally we need total hours of work in @totalHours column
- In the return statement we calculate the percentage of Hours spent in each category to Total hours
Difference between the linear calculation and weighted is the following:
- We need one more table to filter out excavators which may break the logic of calculation with their zero time (because they have laddle volume)
- and in the return statement we use the weighted average formula instead of linear one
So it turns out to be not that hard. Now lets breakdown the measure for breakpoints that have different color and logic in the chart.
Breakpoints time calculation
VAR _breakPoint = SELECTEDVALUE('_idlesDIM'[Sorting])
VAR _base = ADDCOLUMNS(
SUMMARIZE('_vehiclesDIM',
'_vehiclesDIM'[_vehicleName]),
"@vol",
CALCULATE(
MAXX('_vehiclesDIM','_vehiclesDIM'[_ladleVolume])),
"@active",
CALCULATE(
MAXX('_FACT','_FACT'[_active]),
ALL('_idlesDIM')),
"@hours",
SWITCH(TRUE(),
_breakPoint = 6,
CALCULATE(
SUMX(
FILTER('_FACT',
'_FACT'[_active] = 1),
'_FACT'[duration]),
FILTER(ALL('_idlesDIM'),
'_idlesDIM'[Sorting] IN {2,3,4,5})) / 3600,
_breakPoint = 24,
CALCULATE(
SUMX(
FILTER('_FACT',
'_FACT'[_active] = 1),
'_FACT'[duration]),
FILTER(ALL('_idlesDIM'),
'_idlesDIM'[Sorting] IN {2,3,4,5,7,8,9,10,11,12,14,15,21,22})) / 3600,
_breakPoint = 27,
CALCULATE(
SUMX(
FILTER('_FACT',
'_FACT'[_active] = 1),
'_FACT'[duration]),
FILTER(ALL('_idlesDIM'),
'_idlesDIM'[Sorting] IN {2,3,4,5,7,8,9,10,11,12,14,15,21,22,25,26})) / 3600,
CALCULATE(
SUMX(
FILTER('_FACT',
'_FACT'[_active] = 1),
'_FACT'[duration])) / 3600),
"@totalHours",
CALCULATE(
SUM('_FACT'[duration]),
FILTER(ALL('_idlesDIM'),
'_idlesDIM'[Sorting] = 1)) / 3600)
VAR _percent = ADDCOLUMNS(
FILTER(_base,
[@active] = 1),
"@percent",
SWITCH(TRUE(),
_breakPoint IN {6,24,27},
1 - ([@hours] / [@totalHours]),
[@hours] / [@totalHours]))
RETURN
SWITCH(TRUE(),
_breakPoint = 1,
DIVIDE(
SUMX(_percent, [@hours]),
SUMX(_percent, [@totalHours])),
_breakPoint IN {6,24,27},
IF(
ISBLANK(SUMX(_percent,[@totalHours])),
0,
DIVIDE(
SUMX(_percent, [@percent] * [@vol]),
SUMX(_percent, [@vol]))),
BLANK())
So calculation of breakpoint is a bit more trickier but still follows the same logic as above measures:
- We need a breakpoint captured in VAR
- Then we create a virtual table and add attributes
- In @hours attribute we add some logic to calculate breakpoints: with a SWITCH function we check if it s a breakpoint and then calculate all the hours for ordinary categories in total prior to that breakpoint
- In addition we need one more virtual table based on the previous one (VAR _percent): there we need to calculate how much in percentage did that breakpoint cost compared to Total time
- In the RETURN statement we add more logic: calculating the very first bar on the chart and making calculations only for breakpoints skipping ordinary categories
Calculating blank bars
We need one more measure to calculate bars that will just occupy space and leave the visible bars "hanging in the air" and making a waterfall.
VAR _breakPoint = SELECTEDVALUE('_idlesDIM'[Sorting])
VAR _base = ADDCOLUMNS(
SUMMARIZE('_vehiclesDIM',
'_vehiclesDIM'[_vehicleName]),
"@vol",
CALCULATE(
MAXX('_vehiclesDIM','_vehiclesDIM'[_ladleVolume])),
"@active",
CALCULATE(
MAXX('_FACT','_FACT'[_active]),
ALL('_idlesDIM')),
"@hours",
SWITCH(TRUE(),
_breakPoint = 2,
CALCULATE(
SUMX(
FILTER('_FACT',
'_FACT'[_active] = 1),
'_FACT'[duration]),
FILTER(ALL('_idlesDIM'),
'_idlesDIM'[Sorting] IN {2})) / 3600,
_breakPoint = 3,
CALCULATE(
SUMX(
FILTER('_FACT',
'_FACT'[_active] = 1),
'_FACT'[duration]),
FILTER(ALL('_idlesDIM'),
'_idlesDIM'[Sorting] IN {2,3})) / 3600,
_breakPoint = 4,
CALCULATE(
SUMX(
FILTER('_FACT',
'_FACT'[_active] = 1),
'_FACT'[duration]),
FILTER(ALL('_idlesDIM'),
'_idlesDIM'[Sorting] IN {2,3,4})) / 3600,
_breakPoint = 5,
CALCULATE(
SUMX(
FILTER('_FACT',
'_FACT'[_active] = 1),
'_FACT'[duration]),
FILTER(ALL('_idlesDIM'),
'_idlesDIM'[Sorting] IN {2,3,4,5})) / 3600,
_breakPoint = 7,
CALCULATE(
SUMX(
FILTER('_FACT',
'_FACT'[_active] = 1),
'_FACT'[duration]),
FILTER(ALL('_idlesDIM'),
'_idlesDIM'[Sorting] IN {2,3,4,5,7})) / 3600,
_breakPoint = 8,
CALCULATE(
SUMX(
FILTER('_FACT',
'_FACT'[_active] = 1),
'_FACT'[duration]),
FILTER(ALL('_idlesDIM'),
'_idlesDIM'[Sorting] IN {2,3,4,5,7,8})) / 3600,
_breakPoint = 9,
CALCULATE(
SUMX(
FILTER('_FACT',
'_FACT'[_active] = 1),
'_FACT'[duration]),
FILTER(ALL('_idlesDIM'),
'_idlesDIM'[Sorting] IN {2,3,4,5,7,8,9})) / 3600,
_breakPoint = 10,
CALCULATE(
SUMX(
FILTER('_FACT',
'_FACT'[_active] = 1),
'_FACT'[duration]),
FILTER(ALL('_idlesDIM'),
'_idlesDIM'[Sorting] IN {2,3,4,5,7,8,9,10})) / 3600,
_breakPoint = 11,
CALCULATE(
SUMX(
FILTER('_FACT',
'_FACT'[_active] = 1),
'_FACT'[duration]),
FILTER(ALL('_idlesDIM'),
'_idlesDIM'[Sorting] IN {2,3,4,5,7,8,9,10,11})) / 3600,
_breakPoint = 12,
CALCULATE(
SUMX(
FILTER('_FACT',
'_FACT'[_active] = 1),
'_FACT'[duration]),
FILTER(ALL('_idlesDIM'),
'_idlesDIM'[Sorting] IN {2,3,4,5,7,8,9,10,11,12})) / 3600,
_breakPoint = 14,
CALCULATE(
SUMX(
FILTER('_FACT',
'_FACT'[_active] = 1),
'_FACT'[duration]),
FILTER(ALL('_idlesDIM'),
'_idlesDIM'[Sorting] IN {2,3,4,5,7,8,9,10,11,12,14})) / 3600,
_breakPoint = 15,
CALCULATE(
SUMX(
FILTER('_FACT',
'_FACT'[_active] = 1),
'_FACT'[duration]),
FILTER(ALL('_idlesDIM'),
'_idlesDIM'[Sorting] IN {2,3,4,5,7,8,9,10,11,12,14,15})) / 3600,
_breakPoint = 21,
CALCULATE(
SUMX(
FILTER('_FACT',
'_FACT'[_active] = 1),
'_FACT'[duration]),
FILTER(ALL('_idlesDIM'),
'_idlesDIM'[Sorting] IN {2,3,4,5,7,8,9,10,11,12,14,15,21})) / 3600,
_breakPoint = 22,
CALCULATE(
SUMX(
FILTER('_FACT',
'_FACT'[_active] = 1),
'_FACT'[duration]),
FILTER(ALL('_idlesDIM'),
'_idlesDIM'[Sorting] IN {2,3,4,5,7,8,9,10,11,12,14,15,21,22})) / 3600,
_breakPoint = 25,
CALCULATE(
SUMX(
FILTER('_FACT',
'_FACT'[_active] = 1),
'_FACT'[duration]),
FILTER(ALL('_idlesDIM'),
'_idlesDIM'[Sorting] IN {2,3,4,5,7,8,9,10,11,12,14,15,21,22,25})) / 3600,
0),
"@totalHours",
CALCULATE(
SUM('_FACT'[duration]),
FILTER(ALL('_idlesDIM'),
'_idlesDIM'[Sorting] = 1)) / 3600)
VAR _percent = ADDCOLUMNS(
FILTER(_base,
[@active] = 1),
"@percent",
SWITCH(TRUE(),
_breakPoint in {2,3,4,5,7,8,9,10,11,12,14,15,21,22,25},
1 - ([@hours] / [@totalHours]),
0))
RETURN
SWITCH(TRUE(),
_breakPoint = 1,
DIVIDE(
SUMX(_percent, [@hours]),
SUMX(_percent, [@totalHours])),
DIVIDE(
SUMX(_percent, [@percent] * [@vol]),
SUMX(_percent, [@vol])))
So at first glance it looks too long (for no reason) and maybe complex. But the idea and pattern still builds on the previuosly mentioned logic plus some added pattern.
Let me break it down and explain why this turned out to be so long:
- There s a pattern in VAR _base when we calculate @hours. It actually imitates (yes in a long straight forward way) cumulative amount.
- For every ordinary category we need to sum up time from all the previous categories plus current category time
- This pattern goes for every category because i needed to keep the big list available for amendments eg. to add new categories, remove categories or skip (hide/show) categories. But to keep the full list. It could be done in a few different ways but i decided to go with this long version since calculation for every category is clear and you can track the flow and logic for each point.
- In VAR _percent we calculate the remaining percentage instead of the total by subtracting the amount from 1 (aka 100%)
- Finally in the return statement we just calculate the weighted average.
Additional thoughts
When thinking of a chart (bar chart in this case) and logic behind each category calculation you may imagine (like a small kid) the following:
- The imaginary worker under the hood accepts your request to perform some logic & calculation (which you explain to him with DAX)
- When you provide this worker with instructions he starts going from top to bottom of the chart calculating each bar separately taking into account the name of the current category from the Y axis and other attributes (see the next point)
- Additionally you tell him to implement provided logic with some special requests (eg external filters that come from slicers like Date, Type etc)